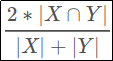Whenever I start a new computer vision competition on Kaggle, I instinctively dust off my trusty set of ImageNet weights, load them up into a ResNet XResNet, begin training and watch as my GPU spins up and the room begins to warm. The nice thing about this approach is that my room doesn’t get as warm as it used to when I initialized my networks with random weights. All this is to say: Pretraining a neural network on ImagetNet lets us train on a downstream task faster and to a higher accuracy.
However, sometimes I dig into the rules of a competition and see things like:
You may not use data other than the Competition Data to develop and test your models and Submissions.
Even worse, sometimes my ImageNet weights just aren’t, like, helping very much. This is especially noticeable in the medical domain when the images we’re looking at are quite a bit different than the natural images found in ImageNet. If we put on our “ML Researcher” hats for a second, we would probably say this is because images from the natural world and images from an MRI “come from different distributions”:


Jeremy Howard from fast.ai covers this in more detail in a recent post on self-supervised learning. He says:
However, as this paper notes, the amount of improvement from an ImageNet pretrained model when applied to medical imaging is not that great. We would like something which works better but doesn’t will need a huge amount of data. The secret is “self-supervised learning”.
You should definitely read it, but a quick summary might sound something like:
Self-supervised learning is when we train a network on pretext task and then train that same network on a downstream task that is important to us. In some sense, pretraining on ImageNet is a pretext task and the Kaggle competition we’re working on is the downstream task. The catch here is that we’d like to design a pretext task that doesn’t require sitting down to hand label 14 million images.
The Holy Grail of self-supervised learning would be to find a set of techniques that improve downstream performance as much as pretraining on ImagetNet does. Such techniques would likely lead to broad improvements in model performance in domains like medical imaging where we don’t have millions of labeled examples.
Imagenette, ImageWoof, and Image网 Datasets
So if these techniques could have such a huge impact, why does it feel like relatively few people are actively researching them? Well, for starters most recent studies benchmark their performance against ImageNet. Training 90 epochs of ImageNet on my personal machine would take approximately 14 days! Running an ablation study of self-supervised techniques on ImageNet would take years and be considered by most to be an act of deep self-hatred.
Lucky for us, Jeremy has curated a few subsets of the full ImageNet dataset that are much easier to work with and early indications suggest that their results often generalize to the full ImageNet (when trained for at least 80 epochs). Imagenette is a subset of ImageNet that contains just ten of its most easily classified classes. ImageWoof is a subset of ImageNet that contains just ten of its most difficult-to-classify classes. As the name suggests, all the images contain different breeds of dogs.
Image网 (or ImageWang) is a little different. It’s a brand new blend of both Imagenette and ImageWoof that contains:
- A
/trainfolder with 20 classes - A
/valfolder with 10 classes (all of which are contained in/train) - An
/unsupfolder with 7,750 unlabeled images
The reason Image网 is important is because it’s the first dataset designed to benchmark self-supervised learning techniques that is actually usable for independent researchers. Instead of taking 14 days to train 90 epochs, we’re looking at about 30 minutes.
For our first Image网 experiment, let’s just try to establish that self-supervised learning works at all. We’ll choose a pretext task, train a network on it and then compare its performance on a downstream task. In later posts we’ll build off of this foundation, trying to figure out what techniques work and what don’t.
Pretext Task: Inpainting on Image网
Full Notebook: Available on GitHub
Over the years people have proposed dozens of pretext tasks, and the one we’re going to look today at is called Inpainting. The basic idea is to take an image, remove patches of it and tell our model to fill in the missing pieces. Below, the removed patches have been highlighted in green:

This approach is described in Context Encoders: Feature Learning by Inpainting. Their claim is that by training on this pretext task, we can improve performance on downstream tasks:
We quantitatively demonstrate the effectiveness of our learned features for CNN pre-training on classification, detection, and segmentation tasks.
The hope here is that by filling in images repeatedly, our network will learn weights that start to capture interesting information about the natural world (or at least about the world according to Image网). Perhaps it will learn that desks usually have four legs and dogs usually have two eyes. I want to emphasize that this is a hope, and I haven’t yet seen strong evidence of this actually happening. Indeed, in the model output above, notice how the model mistakenly believes the edge of the desk slopes downwards and connects to the the chair. Clearly this model hasn’t learned everything there is to know about how desks and chairs interact.
The complete code for this pretext task is available as a Jupyter Notebook. We create a U-Net with an xresnet34 backbone (though vanilla ResNets worked as well). Next, we create a RandomCutout augmentation that acts only on input images to our network. This augmentation cuts out random patches of input images and was provided by Alaa A. Latif. (He’s currently working with WAMRI on applying these techniques to medical images and has seen some promising results!)
Finally we pass the cutout images through our U-Net which generates an output image of the same size. We simply calculate the loss between the model’s output and the correct un-altered image using PyTorch’s MSELoss.
After training we can take a look at the output and see what our model is generating (cutout regions highlighted in green):

So our model is at least getting the general colors correct, which might not seem like much but is definitely a step in the right direction. There are steps we could take to generate more realistic image outputs, but we only want to go down that path if we think it will improve downstream performance.
The last thing we’re going to do here is save the weights for our xrenset34 backbone. This is the portion of the network that we will take and apply to our downstream task.
Downstream Task: Image网
Full Notebook: Available on GitHub
At the heart of this experiment we are trying to answer the question:
What is better: the best trained network starting with random weights, or the best trained network starting with weights generated from a pretext task?
This may seem obvious but it’s important to keep in mind when designing our experiments. In order to train a network with random weights in the best way possible, we will use the approach that gives the highest accuracy when training from scratch on Imagenette. It comes from best performing algorithms on the ImageNette leaderboard.
To be honest, I’m not sure what the best approach is when it comes to training a network with pretext task weights. Therefore we will try two common approaches: training only head of the network and training the entire network with discriminitive fine-tuning.
This gives us three scenarios we’d like to compare:
- Training an entire model that is initialized with random weights.
- Training the head of a model that is initialized with weights generated on a pretext task.
- Training an entire model that is initialized with weights generated on a pretext task.
The full training code is available as a Jupyter notebook. Each approach was trained for a total of 100 epochs and the results averaged over the course of 3 runs.
The results:
- Random Weights Baseline: 58.2%
- Pretext Weights + Fine-tuning head only: 62.1%
- Pretext Weights + Fine-tuning head + Discriminitive Learning Rate: 62.1%
Basically, we’ve demonstrated that we can get a reliable improvement in downstream accuracy by pre-training a network on a self-supervised pretext task. This is not super exciting in and of itself, but it gives us a good starting point from which to move towards more interesting questions.
My overall goal with this series is to investigate the question: “Can we design pretext tasks that beat ImageNet pretraining when applied to medical images”?
To move toward this goal, we’re going to have to answer smaller, more focused questions. Questions like:
- Does training for longer on our pretext task lead to larger improvements in downstream task performance?
- What pretext task is the best pretext task? (Bonus: Why?)
- Can we train on multiple pretext tasks and see greater improvements?
Special thanks to Jeremy Howard for helping review this post and to Alaa A. Latif for his RandomCutout augmentation.