When you set out to learn about machine learning you’re usually told about the importance of creating a good training, validation and test set. The training set will seem important (we need a good set of data to train on) the test set will seem important (we need a good, fair way to compare our model to other models) but the validation set… well… it doesn’t seem that important. Students are usually so overwhelmed with other aspects of data science that they simply create their validation set by randomly sampling from the original training set.
Indeed on many of the standard benchmark datasets (CIFAR 10, ImageNet, MNIST etc.) random sampling is a perfectly fine way to create a validation set. The training set and test set come from roughly the same distribution so your randomly sampled validation set is a good proxy for the test set. Typically when your model improves on your validation set, you’ll also see improvements on your test set.
A recurring theme I see on Kaggle competitions is that how you create you validation set actually matters. For starters, let’s take a look at what happens when we don’t put in the effort to create a good validation set.
The Data
Kaggle’s Histopathologic Cancer Detection competition was an image recognition competition in which competitors trained models to identify cancer within images. The dataset was created from cross-sections of lymph nodes. Each cross section was divided up into 96x96 images that were labelled:
1if a cancerous tumor was present0otherwise
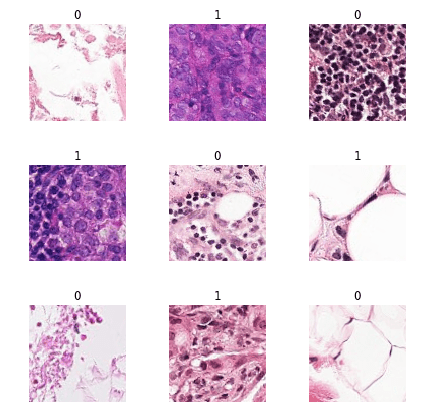
In total there were roughly 200,000 96x96 images in the training set and the labels were evenly balanced.
First Approach
My first approach (guided by years of effective laziness) was to simply create a random validation set using fastai’s split_by_rand_pct. It had served me well in the past, so it wouldn’t let me down here, right?
Below is a plot of test scores vs. validation scores. Note that as validation score increases, test score does not. There is no clear relationship between the two (except perhaps a slightly negative one).
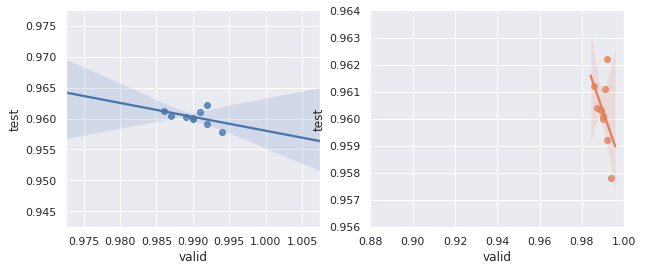
This is a big problem. Many training approaches use validation score to determine the “best” set of weights for a given model. As it stands, an improvement on our validation score does not guarantee us an improvement on the test score.
Revised Approach
While reading the discussion forums on Kaggle I came across SM’s recommendation for a validation set. Instead of sampling randomly, we should group images based on the slide they were taken from and then remove entire slides from our training set. The images from these slides would make up our validation set.
In retrospect this makes sense. Originally we were training our dataset on images that came from the same slides as those in our validation set. When it came time to run our model on the test set we were likely seeing images from slides we’d never seen before.
With our new validation set I decided to re-run my model against the dataset and compare how test score changed as validation score changed:
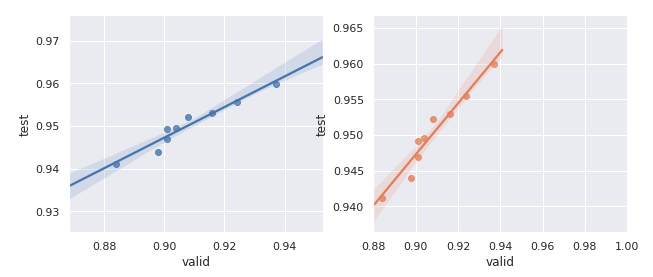
Clearly the relationship between validation score and test scores is much stronger now that we’ve improved our validation set! When we improve our model locally we can expect that we’ll see an improvement on our leaderboard/test score.
