Last month I participated in my first Kaggle competition: Microsoft Malware Prediction. Competitors were given a single train.csv that contained information about millions of people’s PCs. This information included things like screen size, operating system version and various security settings. Competitors were tasked with predicting whether or not a given computer was likely to have been infected with malware.
Exploring the data
Seeing as this was my first Kaggle competition and I didn’t really know what I was doing I started off by heading to look at other user’s public kernels. This is where users share tricks and tips that worked for them. While you’re obviously not going find a solution that wins you the competition, it’s the perfect place for a beginner like myself to start out.
My personal favorite kernel was “My EDA – I want to see all“. This kernel allowed me to look at individual columns in our dataset and gain some intuition on whether or not they might be useful. For example, here is a plot for the Platform column:
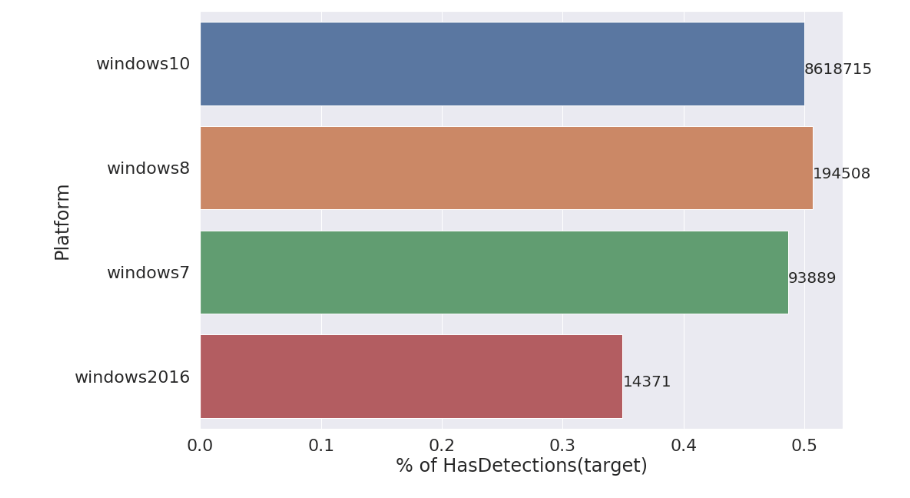
This plot clearly shows that windows2016 is probably a category that might have some degree of predictive power. However this plot also tells us that there are just 14,000 examples of windows2016 out of a total ~9,000,000 so it’s not going to be super useful. Being able to look at columns quickly like this feels like it will be super useful in future competitions and I have incorporated this approach into my KaggleUtils library.
Another interesting discussion demonstrated how we could map Windows Defender versions to dates. This feature helped other users uncover that the test set and train set came from different points in time, which made validation difficult. Both myself and others would see improvements on our own local validation sets, but little or no improvements when we submitted our predictions to the leaderboard. This highlighted the biggest lesson I’ve learned so far:
Creating a good validation set should be my first priority.
On this competition (and a few others I’ve participated in since) this one lesson keeps coming up again and again: You cannot build a good model without a good validation set. It is hard to do, it is tedious to do, but without it you are going into each contest blind.
Cleaning the Data
After exploring the data and getting a sense of what each column meant, it was time to clean the data. This meant dropping columns that wouldn’t help us predict whether a computer had malware. In my case this meant columns that were entirely unique (MachineId) or columns that had >99.99% the same value.
I also dropped categories within columns if those categories were not present in the test set. My thoughts were that if a category wasn’t present in the test set (say a version of Windows Defender) then coming to depend on it for our predictions would hurt performance in the test set.
Finally, I grouped categories that had very small (< 1000) examples in the training set. I figured categories with few examples wouldn’t help us gain much of a predictive edge so I grouped all of these tiny categories into a single OTHER category.
Next I incorporated dates into my training set. After mapping Windows Defender version to dates, I broke those dates into categories like Month, Day and DayOfWeek. I don’t believe this helped my model but it’s an approach I would use in future competitions where predictions might depend on these sorts of things (For example predicting a store’s revenue might depend on whether or not it’s payday).
Model
While everyone successful in this competition used an LGBM, I chose to use a neural network simply because it was what I was most familiar with. I actually started an LGBM approach of my own but didn’t complete it. I wish I had seen it through because it would have helped me understand if my data cleaning approaches gave me any kind of edge.
The data for this competition was largely categorical so LGBM was very well suited to the task. I used neural networks simply because that was what I was familiar with after recently going through fast.ai’s course.
Future Improvements
There was a lot of room for improvement in how I approached this problem and ran my experiments.
- Create a validation set with the same distribution as the test set
- By far the most important change would be to create a validation set with the proper distribution. Some of the kernels even demonstrated how to do this, but out of a personal laziness I ignored them.
- Reproducible Runs
- While exploring hyperparameters I would often just make arbitrary changes I hoped would improve things. Despite using source control I had very little infrastructure to make reproducible runs. I think using this approach would really help me handle my changes in a more manageable way.
- Manage Memory
- Running out of memory was an ongoing problem in this competition. Once EDA was complete I should have focused on shrinking the data’s size. Alternatively I should just buy more RAM.
- Alternative Models
- Although I’m glad I explored my approach with neural networks it was clear that LGBM models were superior on this task. I should have at least tried them out and submitted some predictions.
- Utilities
- Moving forward it would be useful to have a set of common tools for data exploration and cleaning. Many EDA tasks are similar across different competitions so having a semi-standardized approach seems like it would be a huge help. For this reason I’ve started working on a set of Kaggle Utilities.
Conclusion
Ultimately I scored 1,309th out of 2,426 competitors so there was nothing to write home about. I am overall happy with the experience and I’m confident on future competitions I can improve my scores and placements by being diligent and grinding through some of the tedious elements of data science.
