At the end of last year’s retrospective, I set a number of goals for myself. It feels (really) bad to look back and realize that I did complete a single one. I think it’s important to reflect on failures and shortcomings in order to understand them and hopefully overcome them going forward.
Goal 1: Write one blog post every week
Result: 13 posts / 52 weeks
In January 2018 I began the blog series Learn TensorFlow Now which walked users through the very basics of TensorFlow. For three months I stuck to my goal of writing one blog post every week and I’m very proud of how my published posts turned out. Unfortunately during April I took on a consulting project and my posts completely halted. Once I missed a single week I basically gave up on blogging altogether. While I don’t regret taking on a consulting project, I do regret that I used it as an excuse to stop blogging.
This year I would like to start over and try once again to write one blog post per week (off to a rough start considering it’s already the end of January!). I don’t really have a new strategy other than I will resolve not to quit entirely if I miss a week.
Goal 2: Read Deep Learning by Ian Goodfellow
by Ian Goodfellow
Result: 300 pages / 700 pages
When I first started reading this book I was very intimidated by the first few chapters covering the background mathematics of deep learning. While my linear algebra was solid, my calculus was very weak. I put the book away for three months and grinded through Khan Academy’s calculus modules. I say “grinded” because I didn’t enjoy this process at all. Every day felt like a slog and my progress felt painfully slow. Even knowing calculus would ultimately be applicable to deep learning, I struggled to stay focused and interested in the work.
When I came back to the book in the second half of 2018 I realized it was a mistake to stop reading. While the review chapters were mathematically challenging, the actual deep learning portions were much less difficult and most of the insights could be reached without worrying about the math at all. For example, I cannot prove to you that L1 regularization results in sparse weight matrices, but I am aware that such a proof exists (at least in the case of linear regression).
This year I would like to finish this book. I think it might be worth my time to try to implement some of the basic algorithms illustrated in the book without the use of PyTorch or TensorFlow, but that will remain a stretch goal.
Goal 3: Contribute to TensorFlow
Result: 1 Contribution?
In February one of my revised PRs ended up making it into TensorFlow. Since I opened it in December of the previous year I’ve only marked it as half a contribution. Other than this PR I didn’t actively seek out any other places where I could contribute to TensorFlow.
On the plus side, I recently submitted a pull request to PyTorch. It’s a small PR that helps bring the C++ API closer to the Python API. Since it’s not yet merged I guess I should only count this as half a contribution? At least that puts me at one full contribution to deep learning libraries for the year.
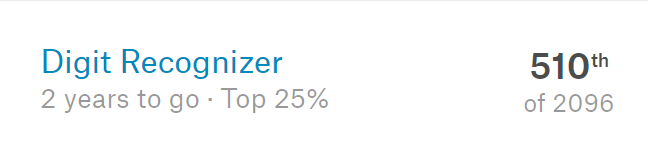
Goal 4: Compete in a more Challenging Kaggle competition
Result: 0 attempts
There’s not much to say here other than that I didn’t really seek out or attempt any Kaggle competitions. In the later half of 2018 I began to focus on reinforcement learning so I was interested in other competitive environments such as OpenAI Gym and Halite.io. Unfortunately my RL agents were not very competitive when it came to Halite, but I’m hoping this year I will improve my RL knowledge and be able to submit some results to other competitions.
Goal 5: Work on HackerRank problems to strengthen my interview skills
Result: 3 months / 12 months
While I started off strong and completed lots of problems, I tapered off around the same time I stopped blogging. While I don’t feel super bad about stopping these exercises (I had started working, after all) I am a little sad because it didn’t really feel like I improved at solving questions. This remains an area I want to improve in but I don’t think I’m going to make it an explicit goal in 2019.
Goal 6: Get a job related to ML/AI
Result: 0 jobs
I did not receive (or apply to) any jobs in ML/AI during 2018. After focusing on consulting for most of the year I didn’t feel like I could demonstrate that I was proficient enough to be hired into the field. My understanding is that an end-to-end personal project is probably the best way to demonstrate true proficiency and something I want to pursue during 2019.
Goals for 2019
While I’m obviously not thrilled with my progress in 2018 I try not to consider failure a terminal state. I’m going to regroup and try to be more disciplined and consistent when it comes to my work this year. One activity that I’ve found both fun and productive is streaming on Twitch. I spent about 100 hours streaming and had a pretty consistent schedule during November and December.
- Stream programming on Twitch during weekdays
- Write one blog post every week
- Finish reading Deep Learning by Ian Goodfellow