Shoutout to my Kaggle partner on this competition: Nathan Hubens
In the Freesound Audio Tagging 2019 competition participants were given audio clips and challenged to write a program that could identify the sounds in each clip. Clips could contain multiple sounds from up to 80 categories.
Here’s a clip that contains both the label Church_bell and Traffic_noise_and_roadway_noise:
The audio clips come from two sources:
- A carefully human-curated dataset
- A noisy dataset with many mislabeled examples
The organizers of this contest wanted to see whether or not participants could find a clever way of using the noisy dataset to improve overall model performance. Labels in both datasets were roughly balanced.
Validation Set
Participants’ programs were tested against a separate, withheld curated test set. This was important to keep in mind when generating a validation set. In order to match our validation set as closely to the test set as possible we wanted to make sure it only contained curated samples as well.
It was also important to ensure that our validation set was label balanced. To achieve this we used an approach called MultiLabelStratifiedKFolds which allows us to generate label-balanced validation sets. Credit to trent-b’s iterative-stratification package for this.
Stuff We Tried That Worked
LogMel Spectrograms – One of the most common approaches in this competition was to take the raw audio input and transform it into a visual spectrogram. After this we could use traditional image recognition techniques (Convolutional Neural Networks) to distinguish between the spectrogram of different sounds. LogMel Spectrograms are widely reported to be the most effective waveform for a deep learning system so that’s what we went with.
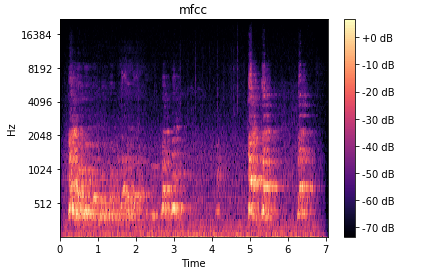
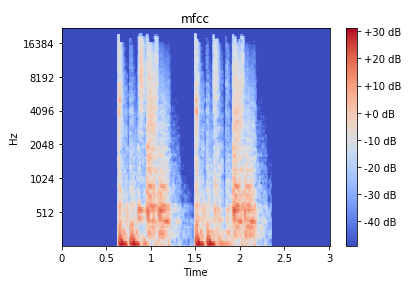
Repeating Short Sounds – The audio sounds varied from less than 1 second to over 50 seconds. Some participants suggested simply padded the short sounds with blank space to make all sounds a minimum of 3 seconds long. However, this meant that large portions of the image contain only silence. Instead, we repeated short sounds multiple times to make them a minimum of 3 seconds long.
XResNet – XResNet is a modification of the traditional ResNet architecture with a few changes suggested by the paper Bag of Tricks for Image Classification with Convolutional Neural Networks.
Test Time Augmentation – The inputs to our neural network are of fixed size (128x128) but the audio clips are of variable length. This can cause problems when the sound we’re trying to identify wasn’t located within the crop we’ve taken. To help compensate for this we make sure to take every sequential crop of an image at test time and average the results. This should help guarantee that a given sound is covered by a crop at some point.
Mixup – A data augmentation technique covered in mixup: Beyond Empirical Risk Minimization. We combine two crops from different images into a single image while also combining their labels. This seemed to help prevent our network from being able to overfit the data as we could create a huge number of combinations of images using different images.
Stuff We Tried That Didn’t Work
Noisy Dataset – We spent a substantial period of time unsuccessfully trying to incorporate the noisy dataset into our system. We tried using label smoothing to reduce the noise introduced by the dataset but still got lower results. We tried finding individual label categories for which the noisy dataset outperformed the clean dataset, but found none.
Using F-Score as a Proxy for Lwlrap – The biggest mistake we made in this contest was trying to use F-score as a proxy metric for lwlrap instead of just using lwlrap metric directly. We figured that as F-score went up so would lwlrap but that was not always the case. Unfortunately we wasted weeks trying to compare approaches and techniques based on F-score. For me this really drilled home the message: “ALWAYS use the competition metric” when designing machine learning systems.
It seems some things just have to be learned the hard way.
Stuff Others Tried That Worked
Noisy Dataset – Other competitors found a lot of success in training the network on the noisy dataset for a number of epochs before switching over and using the curated dataset for the rest of training. This strategy was used by almost every high scoring team.
Data Augmentation – Many competitors used interesting data augmentation techniques such as SpecAugment which masked out entire frequencies or timesteps from audio clips.
Intelligent Ensembling – Some approaches trained multiple models and then ensembled the results of these models. Some combined the results of these models using approaches such as geometric mean blending or an additional MLP.
Results
On the whole the competition went very well. Our team got 95th place out of 880 teams which awarded us both our first Kaggle Bronze Medal!

Our team received an lwlrap score of 0.6943 while the top scoring entry posted a score of 0.7598.

How did you implement label smoothing with multi-class on fastai? I’m looking everywhere but I can’t find a good implementation without concerns that it’s not working properly.. Thanks!
We manually edited the labels ourselves. So instead of having `1` for classes present in each clip, we tried `0.99` and instead of `0` for classes not present in the clip, we tried `0.001`. Our values were chosen arbitrarily and none seemed to help. The results we were getting were here: https://github.com/JoshVarty/AudioTagging/issues/32
I think there are two reasons it failed:
1. Our metric was `lwlrap` which concerns itself primarily with the order in which results are predicted. So if label smoothing makes our classifier output “less confident” results but in the same order then nothing changes.
2. Label Smoothing might work for single class classification because of softmax. Softmax encourages us to create logits that tend toward infinity for the correct class. Since we’re using sigmoid for multi-class, we might not have this issue. See: https://forums.fast.ai/t/is-label-smoothing-off-by-eps-n/44290/10