Full notebook on GitHub.
In Part I, we saw a few examples of image classification. In particular counting objects seemed to be difficult for convolutional neural networks. After sharing my work on the fast.ai forums, I received a few suggestions and requests for further investigation.
The most common were:
- Some transforms seemed uneccessary (eg. crop and zoom)
- Some transforms might be more useful (eg. vertical flip)
- Consider training the model from scratch (inputs come from a different distribution)
- Try with more data
- Try with different sizes
Sensible Transforms
After regenerating our data we can look at it:

Now we can create a learner and train it on this new dataset.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| learner = create_cnn(data, models.resnet34, metrics=error_rate) | |
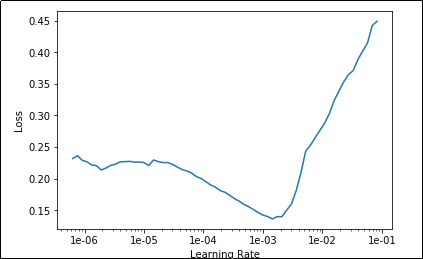
| learner.fit_one_cycle(15, max_lr=slice(1e-4, 1e-2)) |
Which gives us the following output:
| epoch | train_loss | valid_loss | error_rate |
|---|---|---|---|
| 1 | 0.881368 | 1.027981 | 0.425400 |
| 2 | 0.522674 | 3.760669 | 0.758600 |
| … | … | … | … |
| 14 | 0.003345 | 0.000208 | 0.000000 |
| 15 | 0.002617 | 0.000035 | 0.000000 |
Wow! Look at that, this time we’re getting 100% accuracy. It looks like if we throw enough data at it (and use proper transforms) this is a problem that can actually be trivially solved by convolutional neural networks. I honestly did not expect that at all going into this.
Different Sizes of Objects
One drawback of our previous dataset is that the objects we’re counting are all the same size. Is it possible this is making the task too easy? Let’s try creating a dataset with circles of various sizes.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| def generateImagesOfVariousSizes(numberOfPoints): | |
| directory = 'data/countingVariousSizes/' + str(numberOfPoints) + '/' | |
| os.makedirs(directory, exist_ok=True) | |
| #Create 5,000 images of this class | |
| for j in tnrange(5000): | |
| path = directory + str(j) + '.png' | |
| #Get points | |
| x, y = createNonOverlappingPoints(numberOfPoints) | |
| #Create plot | |
| plt.clf() | |
| axes = plt.gca() | |
| axes.set_xlim([-2,2]) | |
| axes.set_ylim([-2, 2]) | |
| #This time we'll generate a random size for each marker | |
| sizes = [random.uniform(25, 250) for _ in range(len(x))] | |
| plt.scatter(x,y, s=sizes) | |
| plt.axes().set_aspect('equal', 'datalim') | |
| #Save to disk | |
| plt.savefig(path) |
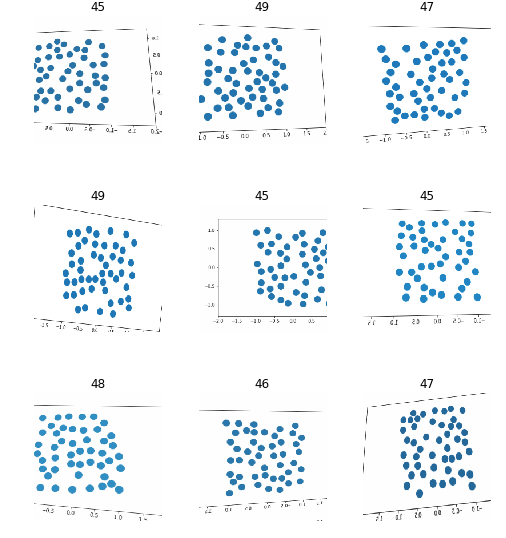
Which allows us to create images that look something like:
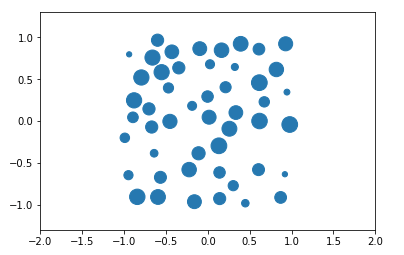
Once again we can create a dataset this way and train a convolutional learner on it. Complete code on GitHub.
Results:
| 1 | 1.075099 | 0.807987 | 0.381000 |
|---|---|---|---|
| 2 | 0.613711 | 5.742334 | 0.796600 |
| … | … | … | … |
| 14 | 0.009446 | 0.000067 | 0.000000 |
| 15 | 0.001920 | 0.000075 | 0.000000 |
Still works! Once again I’m surprised. I had very little hope for this problem but these networks seem to have absolutely no issue with solving this.
This runs completely contrary to my expectations. I didn’t think we could count objects by classifying images. I should note that the network isn’t “counting” anything here, it’s simply putting each image into the class it thinks it would belong to. For example, if we showed it an example with 10 images, it would have to classify it as either “45”, “46”, “47”, “48” or “49”.
More generally, counting would probably make more sense as a regression problem than a classification problem. Still, this could be useful when trying to distinguish between object counts of a fixed and guaranteed range.