Part of the series Learn TensorFlow Now
So far we’ve managed to avoid the mathematics of optimization and treated our optimizer as a “black box” that does its best to find good weights for our network. In our last post we saw that it doesn’t always succeed: We had three networks with identical structures but different initial weights and our optimizer failed to find good weights for two of them (when the initial weights were too large in magnitude and when they were too small in magnitude).
I’ve avoided the mathematics primarily because I believe one can become a machine learning practitioner (but probably not researcher) without a deep understanding of the mathematics underlying deep learning. We’ll continue that tradition and avoid the bulk of the mathematics behind the optimization algorithms. That said, I’ll provide links to resources where you can dive into these topics if you’re interested.
There are three optimization algorithms you should be aware of:
- Stochastic Gradient Descent – The default optimizer we’ve been using so far
- Momentum Update – An improved version of stochastic gradient descent
- Adam Optimizer – Typically the best performing optimizer
Stochastic Gradient Descent
To keep things simple (and allow us to visualize what’s going on) let’s think about a network with just one weight. After we run our network on a batch of inputs we are given a cost. Our goal is to adjust the weight so as to minimize that cost. For example, the function could look something like the following (with our weight/cost highlighted):
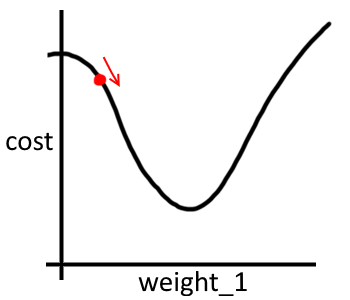
cost
We can obviously look at this function and be confident that we want to increase weight_1. Ideally we’d just increase weight_1 to give us the cost at the bottom of the curve and be done after one step.
In reality, neither we nor the network have any idea of what the underlying function really looks like. We know three things:
- The value of
weight_1 - The
costassociated with our (one-weight) network - A rough estimate of how much we should increase or decrease
weight_1to get a smaller cost
(That third piece of information is where I’ve hidden most of the math and complexities of neural networks away. It’s the gradient of the network and it is computed for all weights of the network via back-propagation)
With these three things in mind, a better visualization might be:
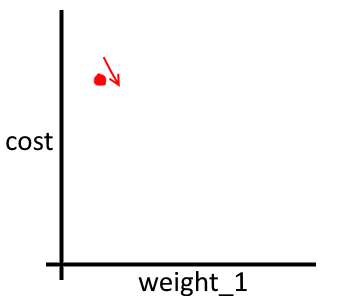
weight_1 now, isn’t it?
So now we still know that we want to increase weight_1, but how much should we increase it? This is partially decided by learning_rate. Increasing learning_rate means that we adjust our weights by larger amounts.
The update step of stochastic gradient descent consists of:
- Find out which direction we should adjust the weights
- Adjust the weights by multiplying
learning_rateby the gradient
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| learning_rate = 0.01 #Some human-chosen learning rate | |
| gradient_for_weight_1 = … #Compute gradient | |
| weight_1 = weight_1 + (-gradient_for_weight1 * learning_rate) #Technically, the gradient tells us how to INCREASE cost, so we go the opposite direction by negating it |
We have been using this approach whenever we have been using tf.train.GradientDescentOptimizer.
Momentum Update
One problem with stochastic gradient descent is that it’s slow and can take a long time for the optimizer to converge on a good set of weights. One solution to this problem is to use momentum. Momentum simply means: “If we’ve been moving in the same direction for a long time, we should probably move faster and faster in that direction”.
We can accomplish this by adding a momentum factor (typically ~0.9) to our previous one-weight example:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| velocity = 0 #No initial velocity. (Defined outside of optimization loop) | |
| … | |
| momentum = 0.9 | |
| learning_rate = 0.01 #Some human-chosen learning rate | |
| gradient_for_weight_1 = … #Compute gradient | |
| velocity = (momentum * velocity) – (gradient_for_weight_1 * learning_rate) #Maintain a velocity that keeps increasing if we don't change direction | |
| weight_1 = weight_1 + velocity |
We use velocity to keep track of the speed and direction in which weight_1 is increasing or decreasing. In general, momentum update works much better that stochastic gradient descent. For a math-focused look at why see: Why Momentum Works.
The TensorFlow momentum update optimizer is available at tf.train.MomentumOptimizer.
Adam Optimizer
The Adam Optimizer is my personal favorite optimizer simply because it seems to work the best. It combines the approaches of multiple optimizers we haven’t looked at so we’ll leave out the math and instead show a comparison of Adam, Momentum and SGD below:
Instead of using just one weight, this example uses two weights: x and y. Cost is represented on the z axis with blue colors representing smaller values and the star represented the global minimum.
Things to note:
- SGD is very slow. It doesn’t make it to the minima in the 120 training steps
- Momentum sometimes overshoots its target
- Adam seems to offer a somewhat reasonable balance between the two
The Adam Optimizer is available at tf.train.AdamOptimizer.
