Part of the series Learn TensorFlow Now
In the last few posts we noticed a strange phenomenon: our test accuracy was about 10% worse than what we were getting on our training set. Let’s review the results from our last network:
Cost: 131.964 Accuracy: 11.9999997318 % ... Cost: 0.47334 Accuracy: 83.9999973774 % Test Cost: 1.04789093912 Test accuracy: 72.5600001812 %
Our neural network is getting ~84% accuracy on the training set but only ~73% on the test set. What’s going on and how do we fix it?
Bias and Variance
Two primary sources of error in any machine learning algorithm come from either underfitting or overfitting your training data. Underfitting occurs when an algorithm is unable to model the underlying trend of the data. Overfitting occurs when the algorithm essentially memorizes the training set but is unable to generalize and performs poorly on the test set.
Bias is error introduced by underfitting a dataset. It is characterized by poor performance on both the training set and the test set.
Variance is error introduced by overfitting a dataset. It is characterized by a good performance on the training set, but a poor performance on test set.
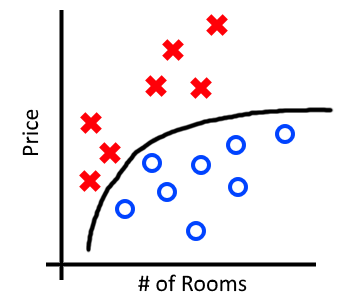
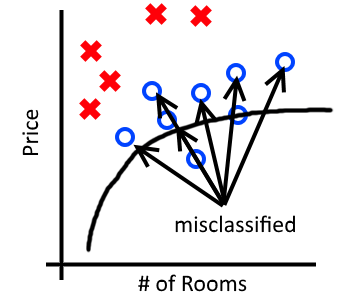
We can look at bias and variance visually by comparing the performance of our network on the training set and test set. Recall our training accuracy of 84% and test accuracy of 73%:

The above image roughly demonstrates which portions of our error can be attributed to bias and variance. This visualization assumes that we could theoretically achieve 100% accuracy. In practice this may not always be the case as other sources of error (eg. noise or mislabelled examples) may creep into our dataset. As an aside, the lowest theoretical error rate on a given problem is called the Bayes Error Rate.
Reducing Error
Ideally we would have a high performance on both the test set and training set which would represent low bias and low variance. So what steps can we take to reduce each of these sources of error?
Reducing Bias
- Create a larger neural network. Recall that high bias is a sign that our neural network is unable to properly capture the underlying trend in our dataset. In general the deeper a network, the more complex the functions it can represent.
- Train it for a very long time. One sanity check for any neural network is to see whether or not it can memorize the dataset. A sufficiently deep neural network should be able to memorize your dataset given enough training time. Although this won’t fix any problems with variance it can be an assurance that your network isn’t completely broken in some way.
- Use a different architecture. Sometimes your chosen architecture may simply be unable to perform well on a given task. It may be worth considering other architectures to see if they perform better. A good place to start with Image Recognition tasks is to try different architectures submitted to previous ImageNet competitions.
Reducing Variance
- Get more data. One nice property of neural networks is that they typically generalize better and better as you feed them more data. If your model is having problems handling out-of-sample data one obvious solution is to feed it more data.
- Augment your existing data. While “Get more data” is a simple solution, it’s often not easy in practice. It can take months to curate, clean and verify a large dataset. One workaround is to artifically generate “new” data by augmenting your existing data. For image recognition tasks this might include flipping or rotating existing images, tweaking color settings or taking random crops of images. This is a topic we’ll explore in greater depth in future posts.
- Regularization. High variance with low bias suggests our network has memorized the training set. Regularization describes a class of modifications we can make to our neural network that either penalizes memorization (eg. L2 regularization) or promotes redundant paths of learning in our network (ie. Dropout). We will dive deeper into various regularization approaches in future posts.
- Use a different architecture. Like reducing bias, sometimes you get the most bang-for-your-buck when you switch architectures altogether. As the deep learning field grows, people are frequently discovering better architectures for certain tasks. Some recent papers have even suggested that the structure of a neural network is more important than any learned weights for that structure.
There’s a lot to unpack here and we’ve glossed over many of the solutions to the problems of bias and variance. In the next few posts we’re going to revisit some of these ideas and explore different areas of the TensorFlow API that allow us to tackle these problems.