2017 saw a lot of change for me. I left Microsoft, returned to Toronto and shifted my focus from developer tools to machine learning. Following in patio11’s footsteps, I wanted to take a moment to reflect on the year and clarify my thoughts in written form.
Microsoft
July 2016 – July 2017
In July 2016, my company Code Connect joined Microsoft with the stated goal of integrating our Alive extension into Visual Studio 2017. Unfortunately our visas were delayed and we weren’t able to begin work until early September. It didn’t make sense to rush Alive into Visual Studio 2017 and risk introducing stability problems so we held off for a few months.
In the meantime, we conducted a number of experiments to try to quantify demand for Alive so we could compare it to other potential features. When the experiments concluded, the data didn’t demonstrate an immediate need for a product like Alive. Alive was put on ice and we worked on features that were immediately pressing to Visual Studio’s success. At the time this meant focusing on accessibility, a top-down directive from Satya Nadella himself.
After Alive was sunset, I did some reflection on where I wanted to take my career and what I wanted to focus on. For a long time I’ve worred that the knowledge I’ve accumulated writing Visual Studio extensions is not immediately applicable outside of Visual Studio. Despite working on developer tools for almost five years, I would be on near-equal footing with a junior developer when it comes to developing extensions for VS Code or Eclipse. Much of my expertise comes in the form of random bits of trivia about Visual Studio. The problems I was faced with were challenging, but not very interesting.
The more I complained, the more I realized something had to change. In July 2017 I left Microsoft and applied for a position at a company for which I’d previously been an intern. However I didn’t have the C++ experience required for the roles they were staffing so we concluded it probably wouldn’t be a great fit.
While at Microsoft I began to learn about machine learning in my free time. In 2015 I’d watched in awe from the sidelines as AlphaGo crushed its human counterparts and I wanted in. I decided that now was the time for me to focus exclusively on machine learning and deep learning in particular.
Would I do it again?
Yup. Alive’s best chance for the long-term was a home at Microsoft. We had a modest number of paying customers but required an order of magnitude more in order to grow and continue full-time work on Alive. We had grand dreams of bringing Alive to other languages and we wouldn’t have been able to do so without hiring more developers. Microsoft came to us at the perfect time and gave Alive one last shot at success. I’m sad it didn’t work out, but I’m eternally grateful to everyone involved in getting us to Microsoft and to the Visual Studio editor team for being my home for the year.
Machine Learning
August 2017 – Ongoing
The hardest thing about starting something brand new is figuring out where to start. I settled on a mix of linear algebra, Coursera, Kaggle and open-source work.
DeepLearning.ai
In September Andrew Ng launched a new deep learning course that covered the following:
- Neural Networks
- Structuring Machine Learning Projects
- Improving Deep Neural Networks
- Convolutional Neural Networks
- Sequence Models
I’ve completed the first four and am waiting for the final course on Sequence Models to launch in the coming month. These courses paired nicely with Andrej Karpathy’s CS231n videos. This course will be my go-to answer for the question “I want to learn about neural networks, where do I start?”
Kaggle
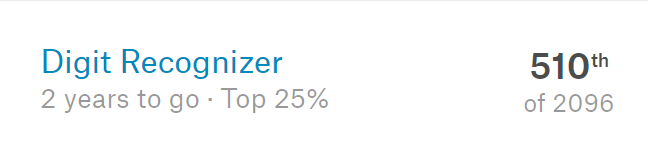
I wanted to apply the lessons I learned in Andrew’s videos to my own neural networks. I set out to compete in the introductory Kaggle competition “MNIST Digit Recognizer”. As I learned more and more about neural networks I would apply these lessons to my network and watch the score improve. Being told “batch normalization will improve your results” is one thing, but watching your score tick higher is something else altogether. As of this writing my best submission puts me in the top 25% of submissions with 99.171% accuracy.
TensorFlow
I set a personal goal to contribute at least one pull request to TensorFlow so as to better understand the tool I was using. Coming from a .NET Desktop background, there was a bit of a learning curve when it came to tools like bazel and Docker. However, like most things in software development these tools just require a bit of time and focused energy to understand.
I’ve seen mixed success with my contributions. My first pull request was a correction to TensorFlow’s implementation of Inception network. The reviewers agreed that the initial model was incorrect, but are hesitant to change the model due to backward compatibility concerns.
My second pull request improved support for various image operations in TensorFlow. In short, it made it easier to augment multiple images at once. (eg. Randomly flipping images left-to-right). Unfortunately, I introduced some performance regressions and my changes had to be reverted. 😢
My third pull request is a re-implementation of the last, while avoiding the performance regressions. It remains open, but I’m confident that after some work it will be accepted.
On the whole, I’m pleased with the progress I made with TensorFlow. The API surface is massive and I have a lot to learn, but I’m making real, measurable progress. I’ll continue to contribute back code where appropriate.
ICLR 2018 Reproducibility Challenge
At the end of each course, Andrew Ng took time to interview famous names in machine learning such as Geoffrey Hinton and Ian Goodfellow. Shared advice they had for newcomers was “Reproduce papers”. Around the same time, I stumbled upon the ICLR 2018 Reproducibility Challenge where students are challenged to reproduce the results of papers submitted to the ICLR conference.
I signed up and chose the paper “Super-Convergence: Very Fast Training of Residual Networks Using Large Learning Rates”. This paper proposed a method for training certain neural networks an order of magnitude faster than previous methods allowed. Their approach involved varying the learning rate linearly between (what are typically considered) large values throughout training.
This was the hardest portion of my work thus far and forced me to delve into the details of TensorFlow. In December I made my report available in the comments of their paper’s submission. The TensorFlow portion of my work is available on GitHub at: http://github.com/JoshVarty/ReproducingSuperconvergence
Blogging
My only regret during 2017 was that I published zero blog posts. As such, this was the first year that traffic to my blog decreased.
I often tell others to start blogging, and this year my actions didn’t match my words. I attribute my poor track-record to one-part laziness and one-part lack of confidence. It’s surprisingly difficult to work up the courage to write about a subject when you’re brand new to it.
Goals for 2018
- Follow Jeff Atwood’s advice for bloggers and stick to a schedule for blogging. I want to buckle down and write one blog post a week in 2018
- Read Ian Goodfellow’s Deep Learning Book
- Contribute to TensorFlow
- Compete in a more challenging Kaggle competition
- Work on HackerRank problems to strengthen my interview skills
- Get a job related to ML/AI (preferably some kind of research role)
